Weekly Review - week of 11/09/2025
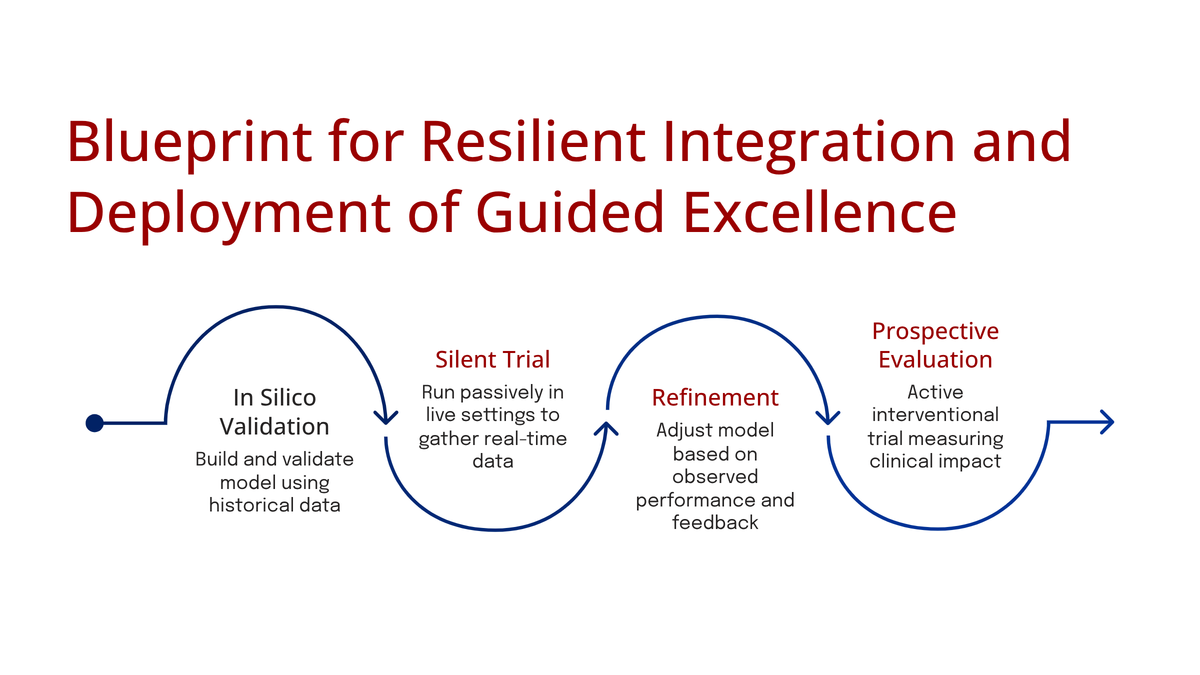
Executive Summary
This week, the focus of leading-edge research and policy has decisively shifted from proving model accuracy (a largely solved problem) to confronting the primary frictions impeding real-world clinical translation.
- The Economics of Validation: A recognition that AI's iterative nature is fundamentally misaligned with the static, costly RCT. A novel trial design (BRIDGE) introduced this week aims to solve this "iteration-to-validation gap," potentially saving millions and months per validation cycle.
- The Architecture of Trust: The conversation has escalated beyond technical trust (uncertainty, bias) to include sociotechnical and regulatory trust. This is evidenced by new research on human factors and, critically, by the AHA's formal policy recommendations to the OSTP, which seek to build regulatory guardrails around payer AI, third-party risk, and "black-box" validation.
- The Modernization of Practice: The academic field is moving to raise its own standards, with AMIA's new "Journal Eligible Initiative" pushing for greater rigor. In parallel, new clinical trials (NCT07226934, NCT07228689) demonstrate the direct application of LLMs in patient-facing communication and as a "gold standard" comparison against human pathologists.
1. The Validation Gap: A Methodological Fix for an Iterative Problem
The most significant methodological contribution this week is the "BRIDGE" (data-reuse RCT design) presented in arXiv:2511.08986. This paper directly attacks the "iteration-to-validation gap"—the crisis that occurs when a 3-5 year RCT validates an AI model (v1.0) that is already obsolete, as the lab is on v4.0.
The BRIDGE Methodology: The design proposes "recycling" participant-level data from completed trials of legacy models. When validating an updated model (v2.0), new recruitment is focused only on "discordant cases"—where the new model's prediction differs from the legacy model's.
- Impact: The authors' simulation reduced required enrollment by 46.6% (9,503 participants) and cut costs by over $2.8 million, all while maintaining 80% statistical power.
- Why It Matters for Informaticists: The validity of BRIDGE rests on "exchangeability," which is operationalized by an "Implementation Consistency" checklist. This checklist moves the problem into our domain, forcing a governance audit of variables like:
- Have imaging acquisition parameters changed?
- Have EHR data dictionaries or clinical workflows been updated?
- Is the new trial data from a GE scanner while the legacy data was from a Siemens?
2. The Trust Imperative: From Technical to Regulatory Architecture
This week, the abstract challenge of "AI trust" was defined in concrete technical and regulatory terms.
A. Technical and Sociotechnical Trust: Research focused on the complex drivers of clinical adoption beyond model performance:
- Uncertainty Quantification (arXiv:2511.05529v2): A selective diabetic retinopathy (DR) screening tool achieved 99.44% accuracy, but at the "cost of certainty"—it had to "abstain" on 69.2% of test samples. This highlights the critical accuracy-vs-coverage trade-off and the need for configurable, not rigid, AI instruments.
- Bias Benchmarking (bioRxiv: 2025.11.12.688133v1): A study on MRI-based cognitive prediction found that ethnic bias is modality-dependent (structural MRI > functional MRI). Critically, it provided a clear mitigation strategy: training on ethnically balanced subsamples reduced disparity without any loss in accuracy.
- Sociotechnical Barriers (arXiv:2511.07277): In a study of AI health tech for Limited English Proficiency (LEP) populations, the primary barriers were not technical (e.g., poor translation) but sociotechnical—the AI "disrupted rapport" and workflow, making it a clinical failure despite its technical accuracy.
B. Regulatory and Policy Trust (AHA Recommendations): The technical concerns above are now being directly reflected in high-level policy. The American Hospital Association (AHA), representing 5,000 hospitals, submitted formal recommendations to the OSTP that seek to build a regulatory framework for trust.
Key demands relevant to informaticists include:
- Mandating Clinician-in-the-Loop: Citing a 2024 AMA survey where 62% of doctors believe payer AI is increasing denials, the AHA demands that a trained clinician "independently review" any AI-driven partial or full denial of services.
- Solving "Black Box" Risk: The AHA directly names the "black box" nature and risk of "hallucinations" as a threat to model integrity, demanding support for premarket and post-deployment testing standards.
- Regulating Third-Party Risk: The AHA notes that third-party vendors (business associates) were responsible for 75% of total individuals affected by breaches in 2024. It demands that third-party AI vendors, even those not currently covered by HIPAA, be held to the same privacy and security standards as covered entities.
3. Modernization in Practice: From AMIA Policy to New RCTs
The final theme is the field's active "modernization," both in its academic standards and its clinical applications.
A. Academic Modernization (AMIA 2025): The AMIA 2025 Annual Symposium's new "Journal Eligible Initiative" is a significant structural change. By creating a direct pathway from conference presentation to high-impact journal publication (JAMIA, ACI), AMIA is formally elevating the scientific and peer-review standards of its flagship conference. This is a direct attempt to solve the "conference-first" (CS) vs. "journal-first" (medicine) culture clash and raise the standard of evidence for informatics interventions.
B. Clinical Application (New RCTs)
- NCT07226934 (WashU - LLMs in Patient Comm.): This study is testing a HIPAA-compliant, ChatGPT-based tool ("GPT-QPL") to generate personalized question prompt lists for lymphoma patients. This is a direct application aimed at solving the sociotechnical and communication barriers identified in the LEP patient research.
- NCT07228689 (Orlando Health - LLMs in Cytology): This trial is assessing whether a ChatGPT-based AI can accurately identify abnormal cells in EUS-FNB cytology specimens for GI tract lesions. The AI's interpretation is being compared directly with expert human pathologists as the "gold standard," testing its viability as a diagnostic partner.
- NCT07227376 (Eko Devices - ML in Diagnostics): This observational cohort study is collecting lung sound data from 250 adults to train and validate ML algorithms for classifying wheezing, crackles, and rhonchi. This represents the necessary, foundational data-gathering to expand Eko's FDA-cleared AI stethoscope platform from cardiology into pulmonology.
Concluding Analysis
The through-line for the week is implementation. The field is actively building the essential "scaffolding" required for real-world deployment: methodological scaffolding (BRIDGE trial), trust scaffolding (AHA policy, bias benchmarks), and disciplinary scaffolding (AMIA initiative, new RCTs). The challenges are no longer theoretical; they are the practical, high-stakes work of translating AI into safe, effective, and equitable clinical care.